CUDA编程笔记:简明扼要-6
这是一篇关于CUDA编程高级概念的笔记
FROM:CUDA Teaching Center Oklahoma State University
Note:本教程并不过多关注细节语法等内容,而是站在更高层次的概念之中。熟练的掌握CUDA编程需要练习,然而对基础概念的把握却需要透彻的理解。
Part6 :线程同步与屏障
由于线程是并行运行的,所以会遇到这样的情况,就是正确的数据还未放置到位,读取动作就发生了,称之为Race
Condition。为了避免竞争的发生,我们需要线程同步。
用显示Barrier实现线程同步
原话:
Threads need to synchronize with one another to avoid race
conditions.线程需要与其他线程同步以避免竞争的发生A barrier is a point in the kernel where all threads stop and wait on the
others.所谓的屏障是一个线程们都停下来去等其他线程的点
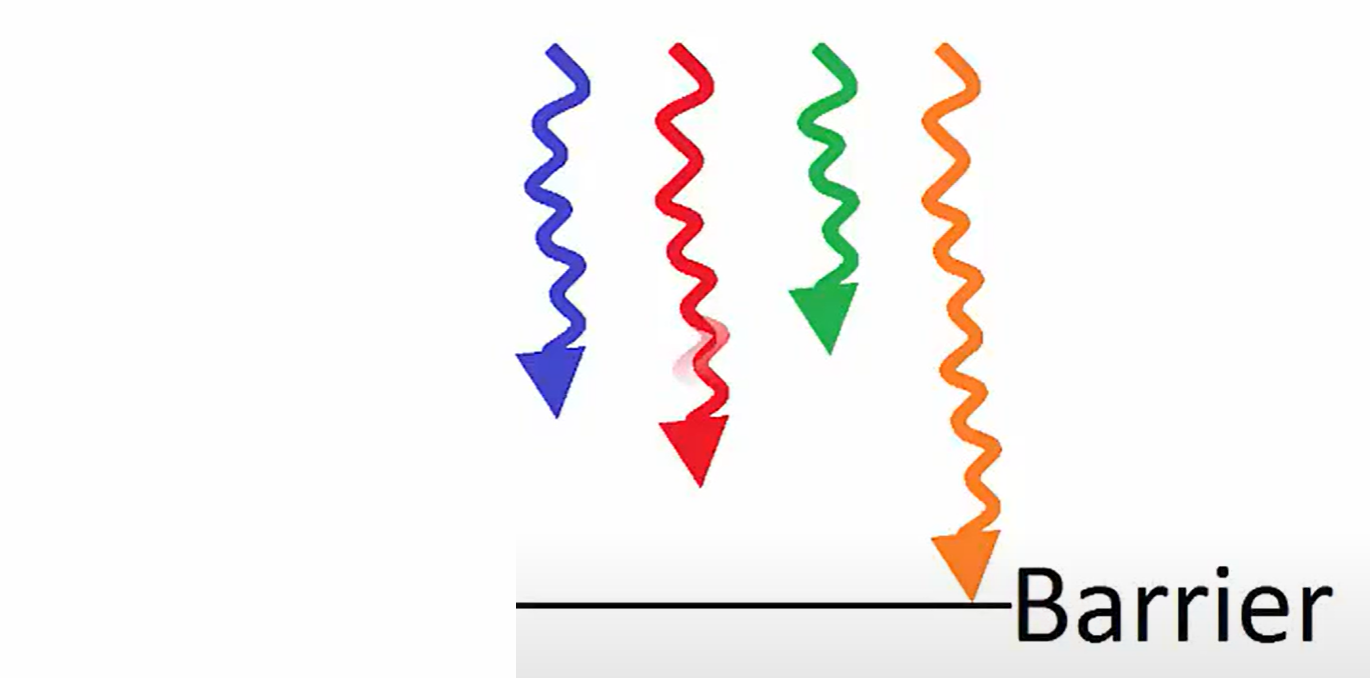
一旦所有的线程都到达此屏障点,我们就说线程已同步,然后允许该块中的线程继续执行
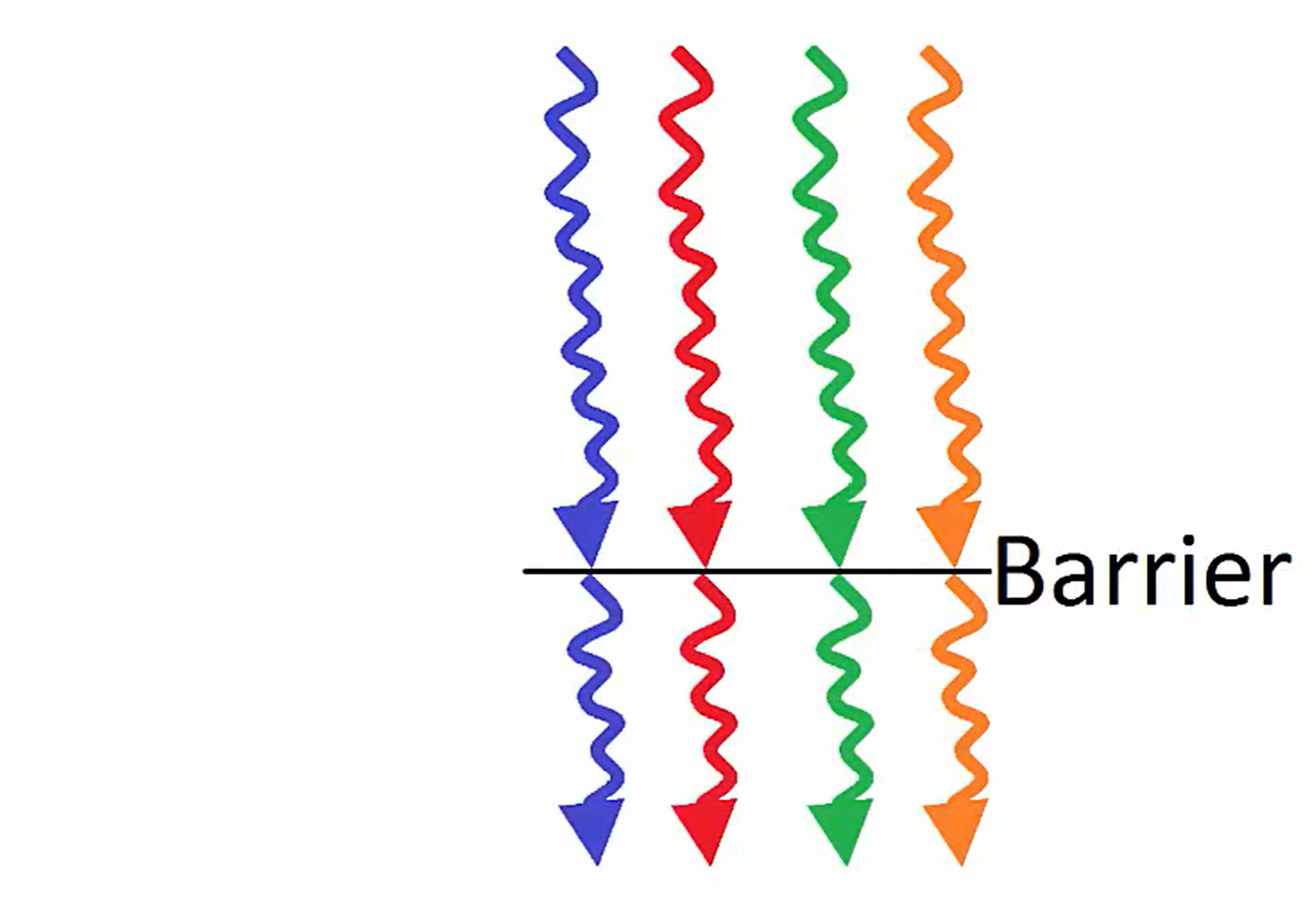
线程同步使用:__synvthreads();显式实现
例子
假设我们要将下面的数组左移一个位置:
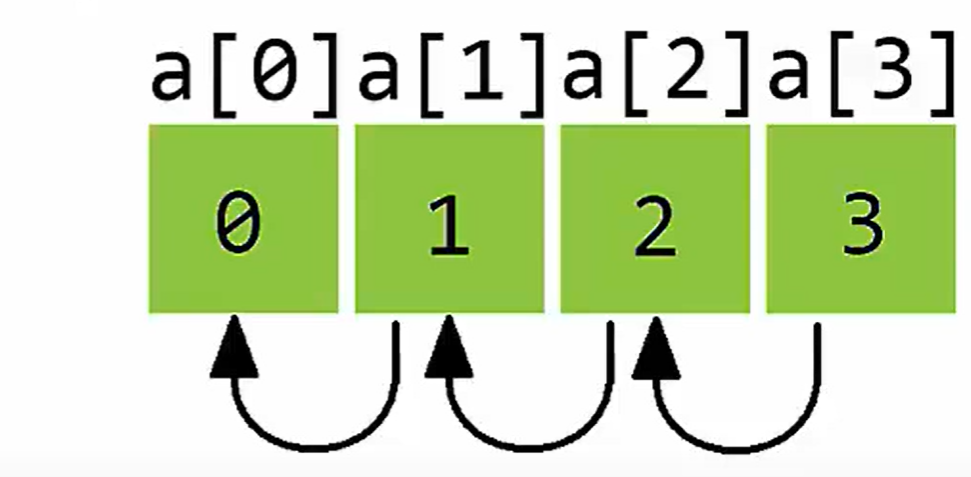
a是位于global区域的数组
实现代码如下:

解释:
if是为了限制长度,我们的数组长度只为4,不限制的话,会在多余4个thread上执行相同操作。
temp = a[i+1],写之前要先读出来。
同步,确保都读完了。
再写入,确保所有都执行完毕。
1 | 启发:看GPU程序时候,不能以cpu的眼光来看,比如说这个temp,实际上在4个线程上都定义了一个叫做temp的变量,存储于各自的寄存器中。 |
kernrl中的同步
CPU并不等待GPU程序的执行,此时可以使用cudaDeviceSynchronize();
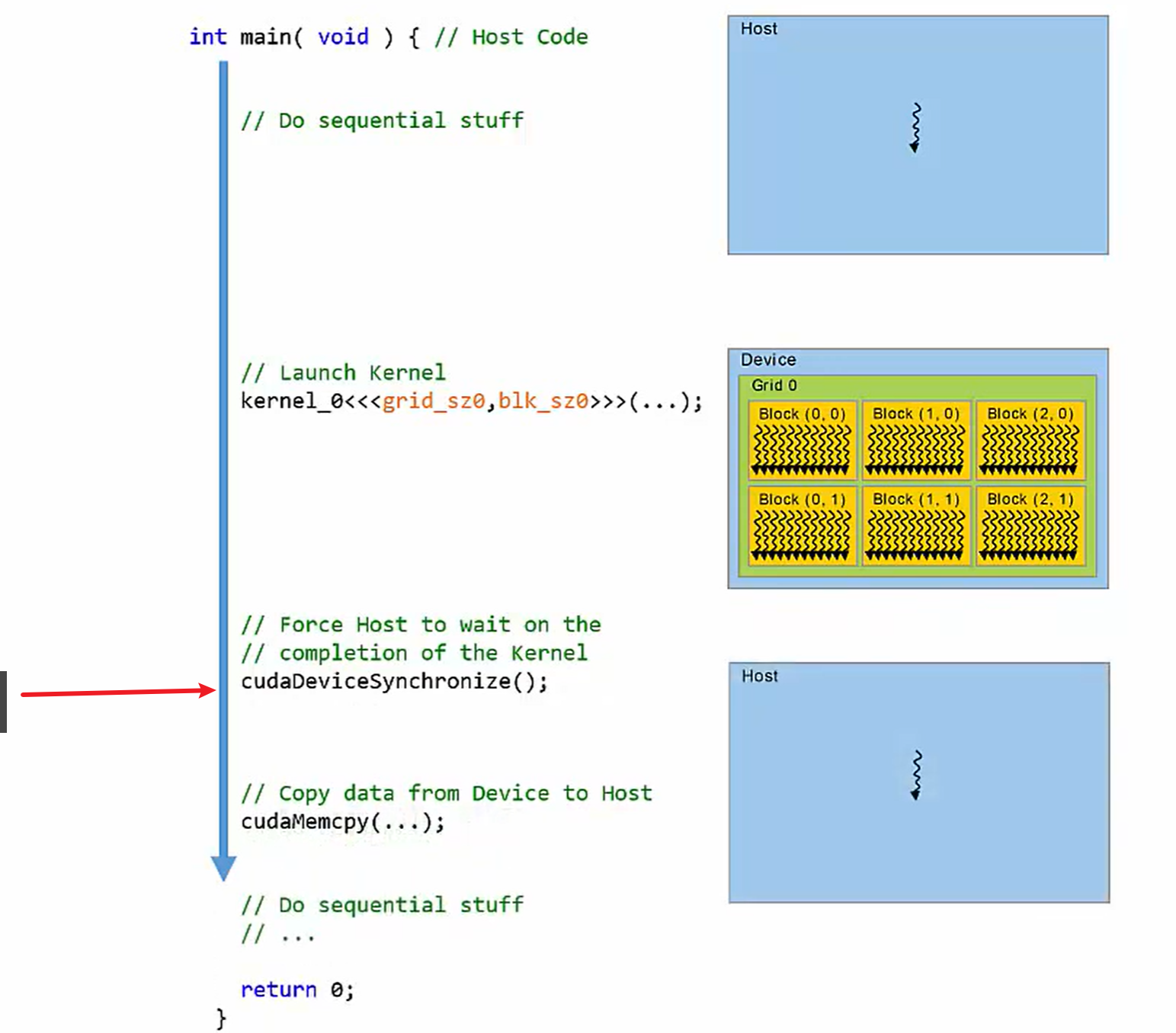
CPU停在红色屏障位置,等到上一个kernel函数执行完毕。
总结
CUDA官方的关键点:
计算的三个层次
内存空间模型
线程同步
