CUDA编程笔记:简明扼要-5
这是一篇关于CUDA编程高级概念的笔记
FROM:CUDA Teaching Center Oklahoma State University
Note:本教程并不过多关注细节语法等内容,而是站在更高层次的概念之中。熟练的掌握CUDA编程需要练习,然而对基础概念的把握却需要透彻的理解。
Part5 : CUDA内存模型
CUDA提出了分区内存空间的概念,以向程序员展示不同层次的并行性和性能。这一点是与C编程的一个大区别。
内存模型也是一个抽象概念,它与线程的层次一一对应,也是有3个层次。
Thread与Memory的对应关系
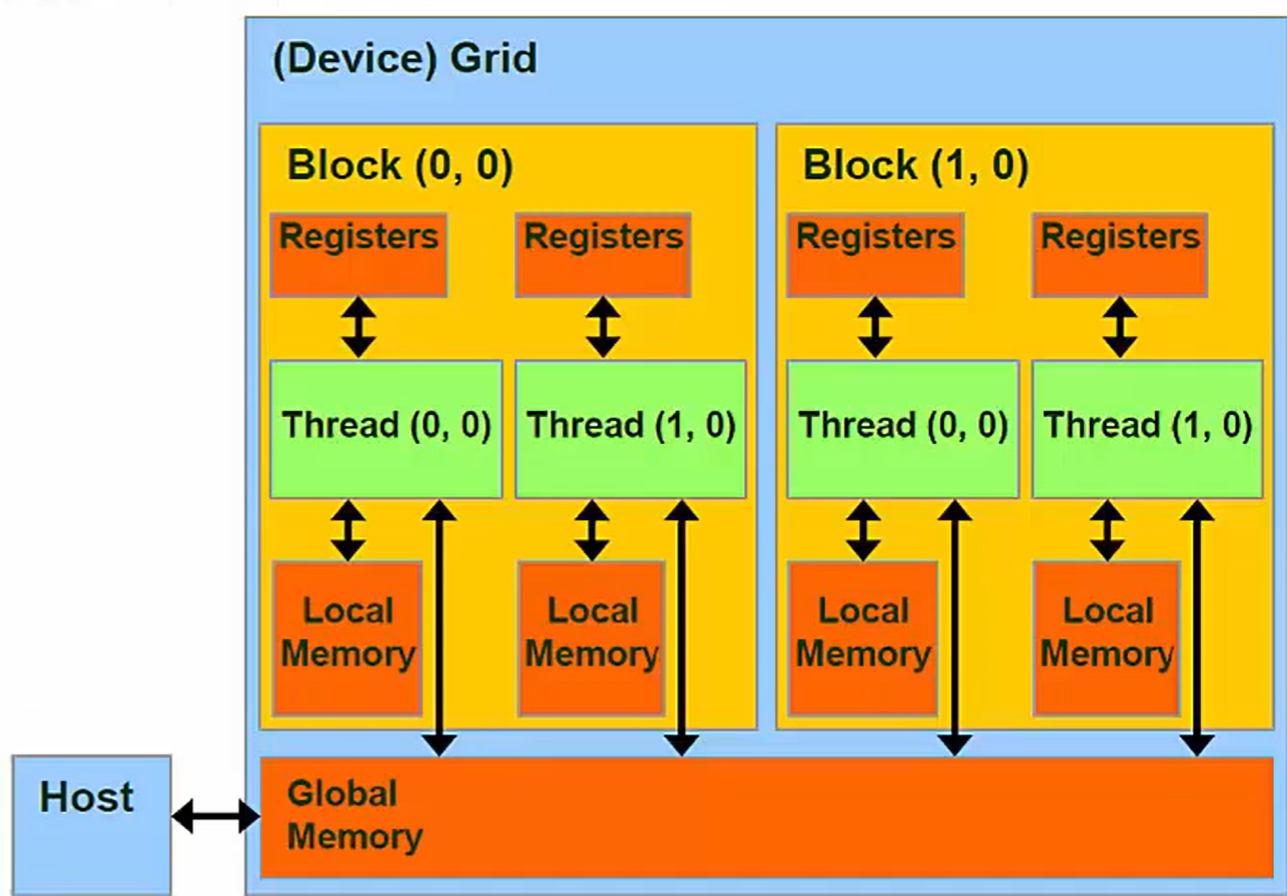
Thread ⇔ Local Memory(and Regesters)
scope:Pritive to its corresponding Thread
Lifetime: Thread

(注:local通常指的是DRAM的空间)
每个线程都有自己的私有本地内存,当一个线程执行完毕之后,任何其他线程都无法访问该线程的内存空间,与该线程相关的任何本地内存都会被自动销毁。
线程也有一些私有寄存器,这些寄存器与本地内存具有相同的范围(scope)和生命周期,但是性能特征却大相径庭。
Blocks ⇔ Shared Memory
scope:Every Thread in the Block has access
Lifetime: Block

该块内的所有线程,都可以访问这一块共享内存。
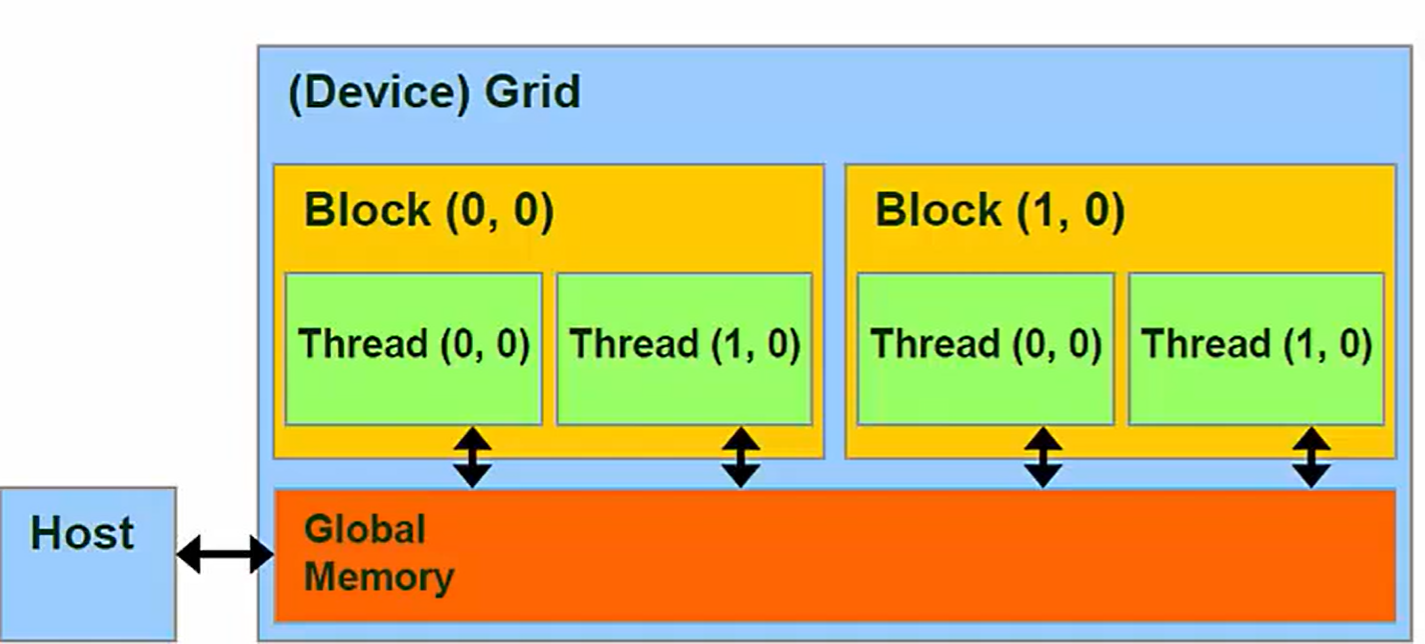
Grids ⇔ Global Memory
scope:Every Thread in all Grids have access
Lifetime: Entire program in Host code - main()
全局内存对于程序的所有线程都是可见的,持续存在于整个程序的生命周期,可以使用cudaFree手动销毁
物理Model

黄色的矩形代表SM’s
- 理解block如何映射到SM上是编写kenel函数从GPU获取最佳性能的基础
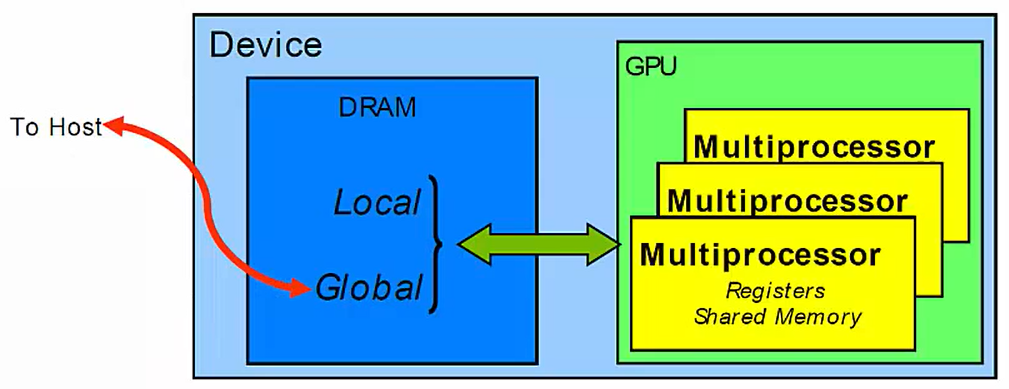
位于SM上的内存称为on-chip(片上)内存
- share memory 、
regesrers,因为其物理上就存在于GPU上(准确的说是存在于GPU的SM上)
- share memory 、
不在SM上的内存称为off-chip(片外)内存
Global memory 、local
memory,因为其物理上不在GPU芯片上,而是存在于GPU板卡上,位于GPU芯片外围(详细见下图)

1
有一个混淆概念:GPU说的是GPU芯片本身,但有时候代指GPU板卡。在讨论细节时候,我们认为其是GPU芯片,在生活中或宏观上,我们认为GPU就是GPU板卡。
不同存储的速度
相对速度如下,此处的速度指的是,综合考虑带宽与延迟的相对速度。
不同的内存类型设计目的也不一样,由于其物理设计不同,每种内存有着截然不同用的带宽和延迟。

Global Memory
访问函数接口:
cudaMalloc()
cudaMenset()
cudaMenCopy()
cudaFree()
全局内存是我们最熟悉的内存,当使用cudaMalloc函数分配内存时,得到的就是这个区域的内存。由于这片内存在外部的DRAM上,他表现出很慢的(very
slow)内存性能,但是我们不可避免的使用这一片内存,因为我们需要在主机和设备之间交换数据。
受此启发,我们的目标就是尽可能减小这一片内存的数据流量。但是他也有一个好处,他的空间比较大,与计算机的RAM相当,通常是8GB
or 16GB,Titan和Tesla K40现在(2018左右吧)都有6GB的global DRAM。
注意:这张图的一个关键是:host与GPU的数据交换通常以Global Memory作为中转站
Regesters and Local Memory
前面已经说过,每一个线程都有自己的Regesters和Local
memory,其他任何线程都无法访问。
内核中声明的任何变量都存储于寄存器
片内的
寄存器是最快的存储类型
如果存储的内容太大,将会溢出到Local memory
片外的
由编译器控制
local指的是scope(可见范围),而不是location(位置)
local to each thread
但是,溢出到Local memory通常不受欢迎,因为local
memory是最慢的存储区域之一。所以,尽可能不要放置超过regester空间大小的数据。寄存器空间是一种稀缺的硬件资源,要关注如何更好的利用这部分资源。
Shared Memory

Allow Threads within a Block to communicate with each other
- Use synchronization
Very fast (on chip)
- Only regesters are faster
共享内存是一种非常特殊的内存空间,对性能和正确性至关重要。从某种意义上说,这片空间是用户定义的一级缓存(实际上它与一级缓存有着千丝万缕的联系)
Using Shared Memory
下面的代码展示了如何在共享内存中声明变量,使用share关键字:

Constant Memory
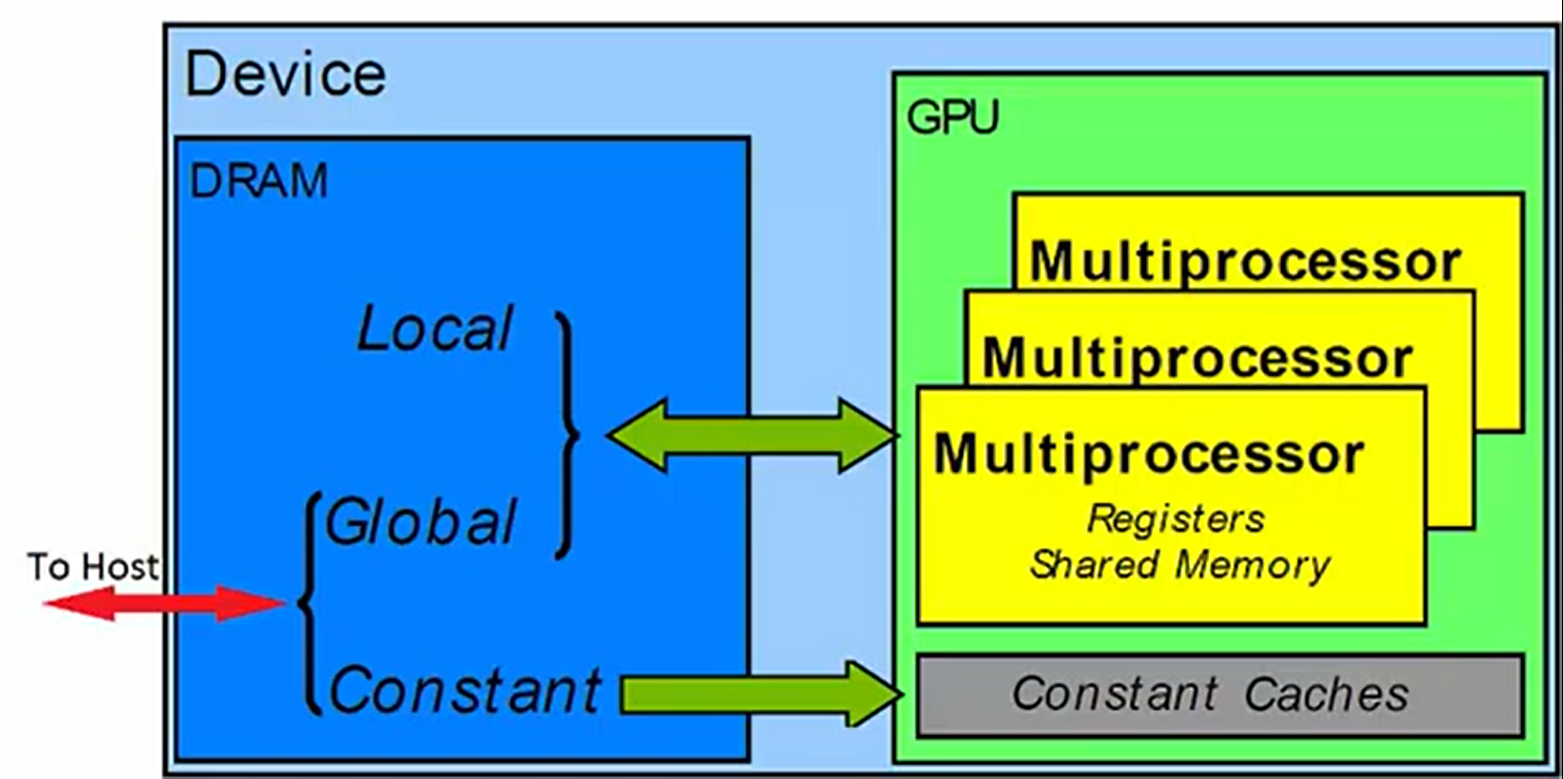
注意:第二个箭头是单向的
Device存储空间的特殊区域
用于保存内核函数执行时候的不变内容
只读
片外
常量内存is aggressively cached into On-Chip menory
这是一个没有相对应的层次的存储空间。由于GPU没有特别大的缓存(这一点与CPU对比很明显),我们可以使用常量空间实现一种很简单的缓存。
常量空间实际上他比较大,因为他位于DRAM,所有线程都可以访问他,但他对于kernel来说,是只读的。我们希望把这部分空间用于保存经常访问但在内核执行期间不变的的数据。尽管他是片外的,但他的内容实际上被积极的缓存(搬运)到片上内存之中.
所以,使用常量空间可以显著减少global存储的数据流量
总结
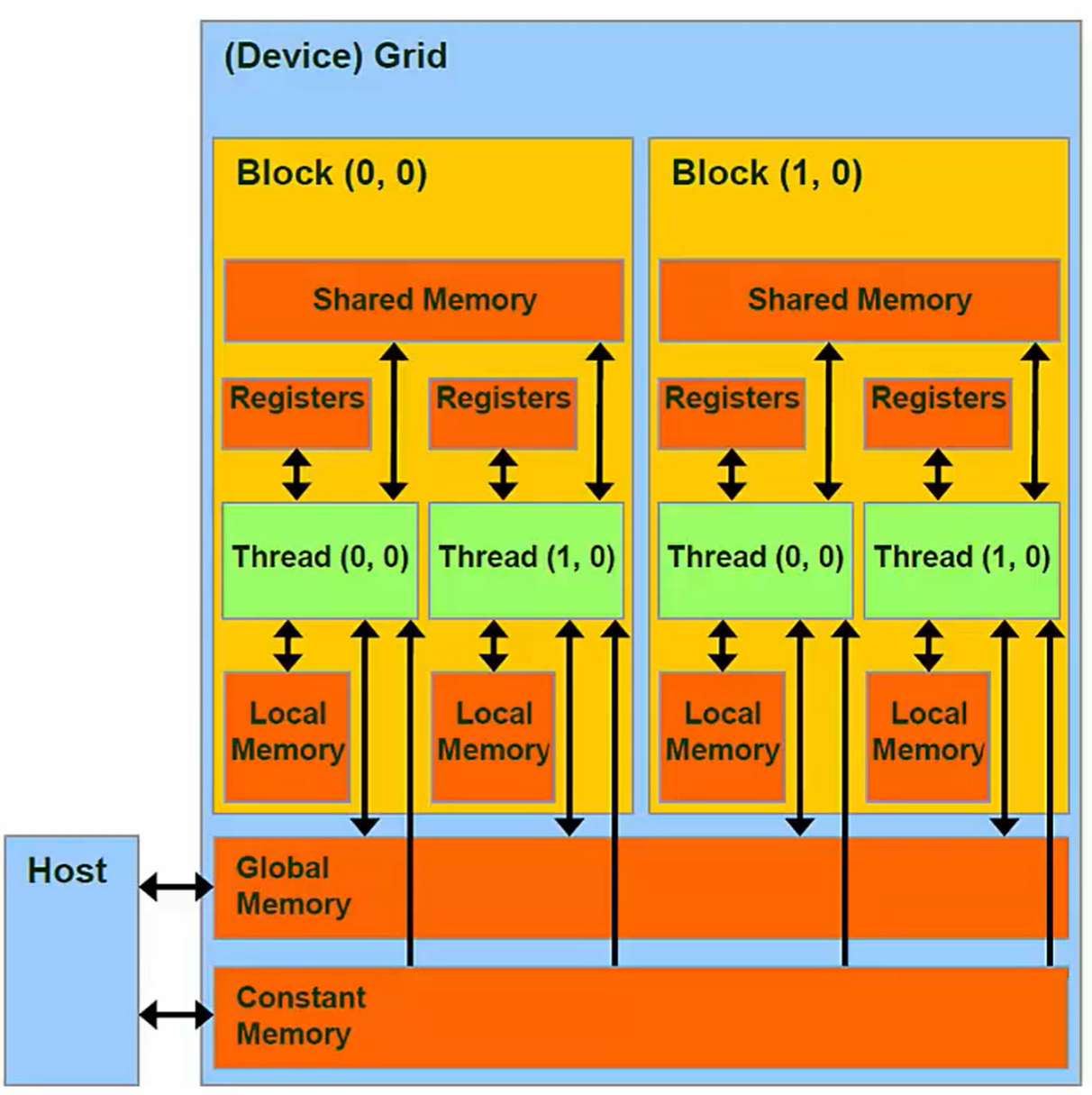
从最低层按照一个程序员的眼光来看,我们拥有寄存器和Local Memory,在核函数内声明的变量都存储与寄存器当中,如果过大,将会溢出到Local Memory,但这是不可取的,因为Local Memory位于片外。
共享内存比较特殊,原因之一是他具有极其快的速度,这一点由片上特性决定;另一点是他允许同一block中的线程进行communicate