CUDA编程笔记:简明扼要-4
这是一篇关于CUDA编程高级概念的笔记
FROM:CUDA Teaching Center Oklahoma State University
Note:本教程并不过多关注细节语法等内容,而是站在更高层次的概念之中。熟练的掌握CUDA编程需要练习,然而对基础概念的把握却需要透彻的理解。
Part4 :在块和网格中索引线程
每一个线程都有唯一的线程索引(标识),这个索引来自kernel函数内置的变量。
内置变量
内置变量在不同层次分为:
Dimension
Index
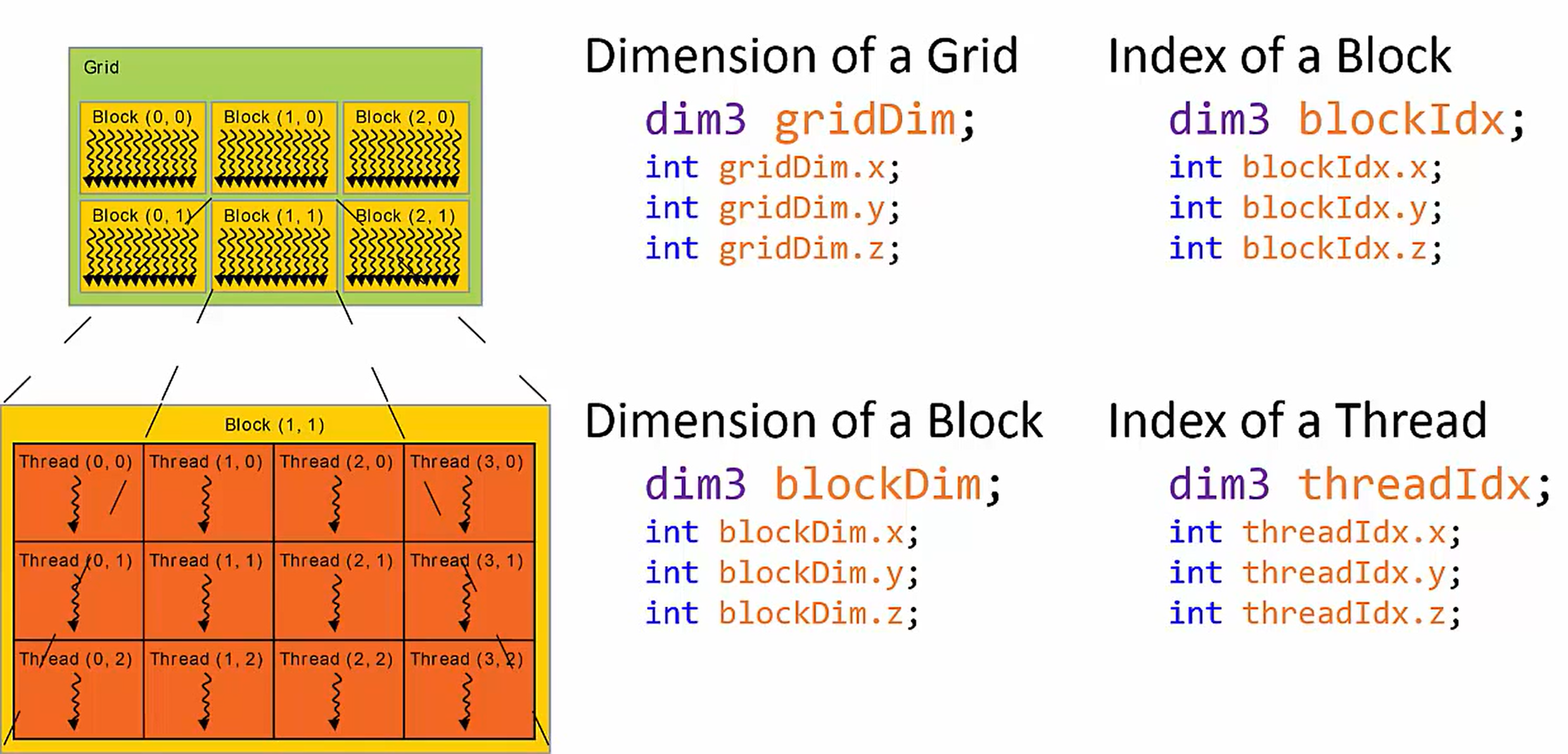
注意:此处有点混淆,dimension指的是“个数”,index针对当前某个grid或者block而言。就像:一共有3个grid,每个grid有6个块,每个块有12个thread
这里的3、6是对维度dimension而言;块的index是为了标识当前的单个块在单个grid的位置;线程的index是为了标识当前的单个thread在单个block的位置;
1 | 为什么会这么绕?我想是因为本来thread的组织就是多层次的,那么在具体描述这件事的时候,就难免会产生很多中间概念,不过理解清楚即可。 |
Grid中的index
为了意思明确,原文说的是:
- threadIdx is only unique within its own Thread Block

也就是说,threadIdx这个内置变量在每个块中都有,且其值可以重复,如上图所示。但是对某个特定块而言,是不会重复的。(虽然唯一,但有限定范围)
那么要想在grid中唯一地标识一个thread,应当这样:
1 | i = threadIdx.x + blockIdx.x * blockDim.x |
其实,根据上述理解,还是很直接的:
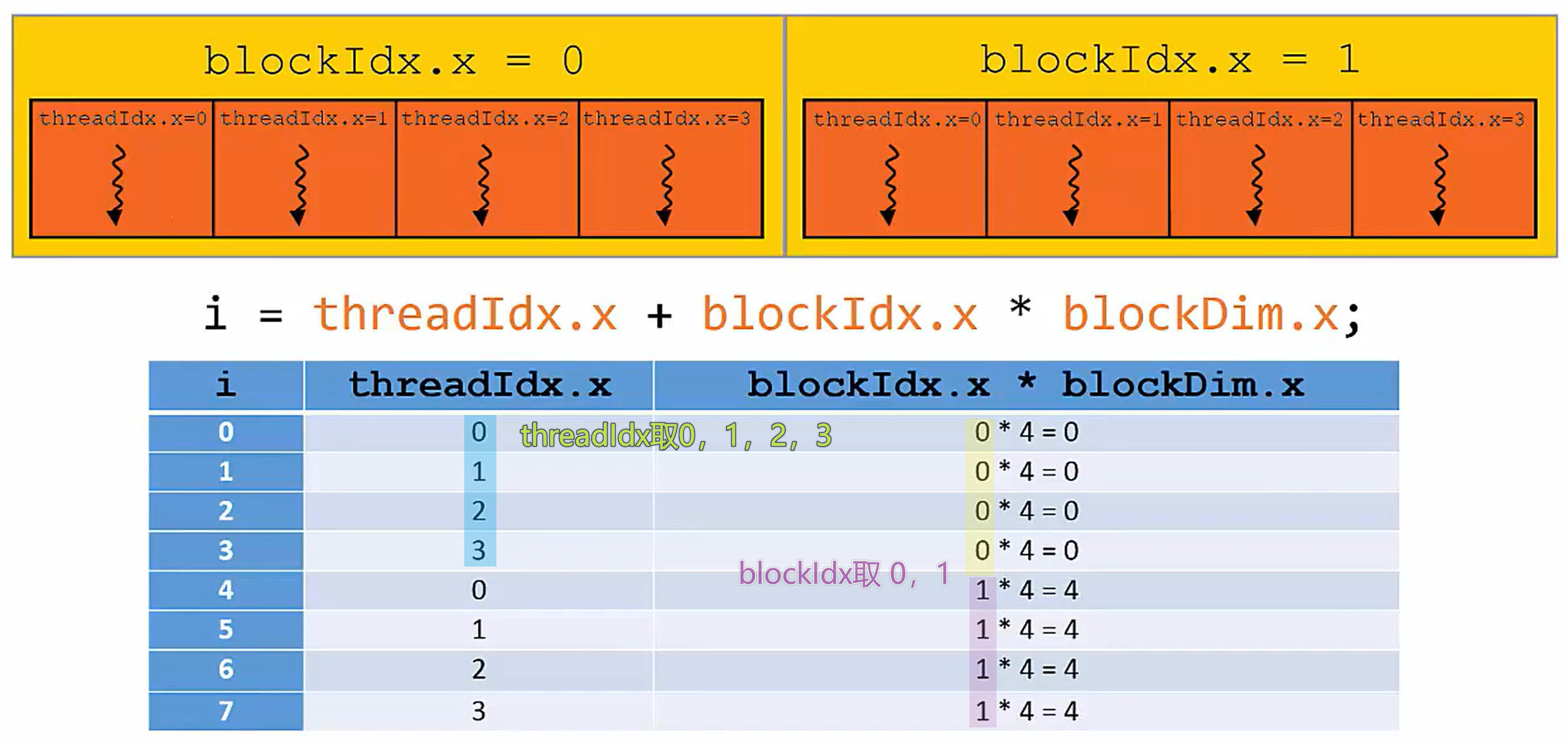
举例

20220617解答:
线程ID快速计算方法
关于索引的问题,一直迷惑,直到6.17日看了手写AI的教程,有一种便于记忆的方法,描述如下:
1 | /* dims indexs |
左边的dims实际上限制了idx的大小,视为tensor里的shape,那么按照“左乘右加”的原则,即可计算线程的实际id:

红色代表累乘(*=),绿色代表累加(+=)
例如:

按照这个原则(准确的说,用的是*=,+=,每一行都会多出来一层小括号,这里不写,太乱)
计算为:
1 | dims indexs |
总结:他这个思想并没有受x y z这三个字母影响,看到xyz总想着把它对应到空间里,所以比较思考比较慢,要是将xyz仅仅视为维度,按照思考tensor的那一套思想,很容易快速写出来线程id。