CUDA编程笔记:简明扼要-2
这是一篇关于CUDA编程高级概念的笔记
FROM:CUDA Teaching Center Oklahoma State University
Note:本教程并不过多关注细节语法等内容,而是站在更高层次的概念之中。熟练的掌握CUDA编程需要练习,然而对基础概念的把握却需要透彻的理解。
Part 2:编程模型(Programming Model)
程序流
在这一部分,将展示CUDA程序是如何在代码中组织的,需要知道重要的一点:CPU处于控制状态,即:Host控制着程序的整个流程,程序的流程就像一个普通的C程序一样,从main函数开始,直到需要uploadGPU代码的部分。

kernel函数启动之后,线程以Grid为单位在GPU执行,kernel函数开始执行之后,程序立即返回到主机继续执行(言外之意:主机并不等待GPU执行完毕),直到遇见另一段GPU代码。
注意:因为主机的main
C函数并不等待内核函数执行完毕,所以,如果要收集特定内核执行的结果,我们需要在主机代码中显式地制造一个barrier(屏障)来告诉mian
C函数等待内核执行完毕,后续详细介绍。
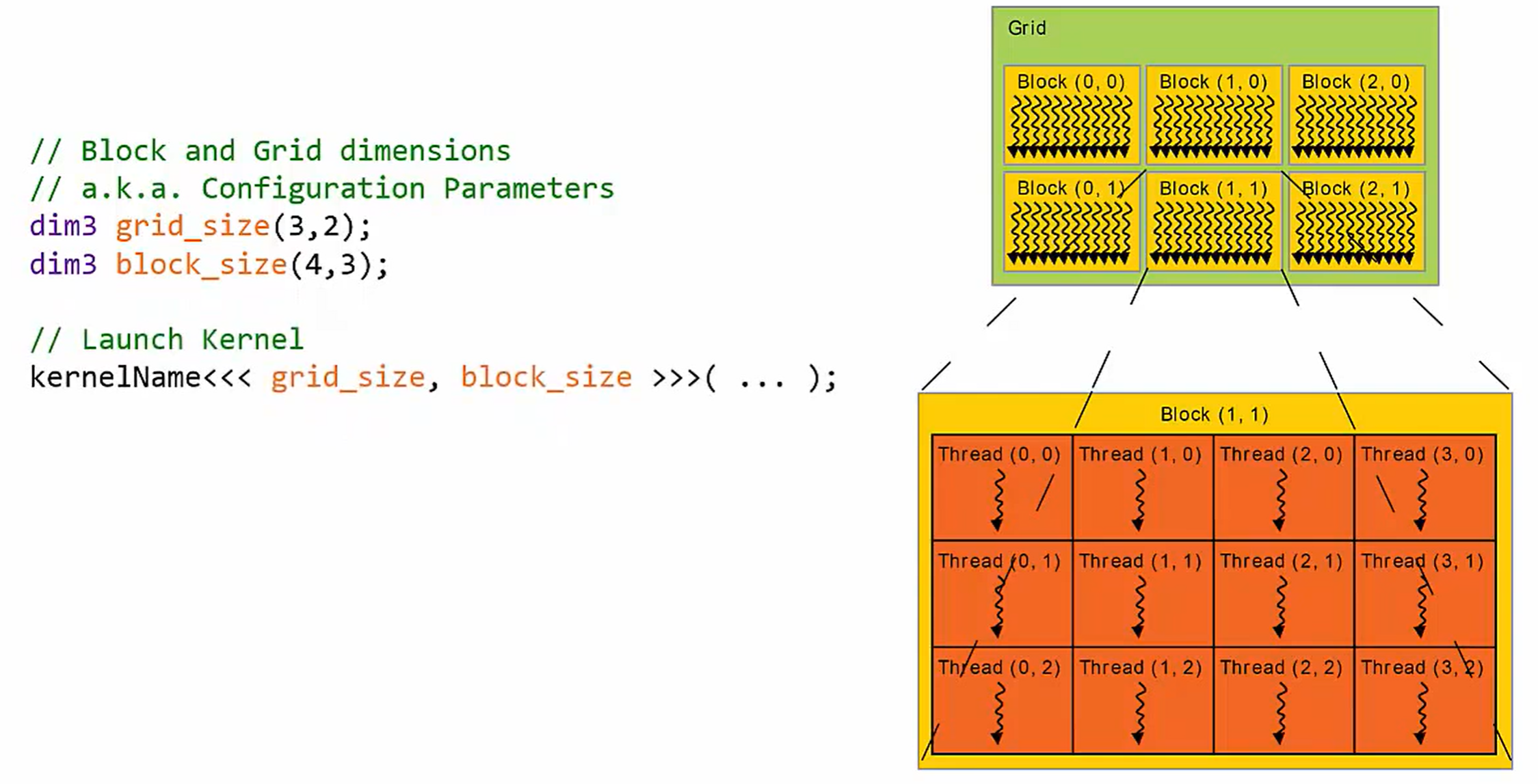
核函数(kernel)启动的语法
核函数的启动就像调用普通的C函数一样,核函数的名称写在前边,参数写在后边的括号里,唯一的不同是,需要在三个尖括号内配置启动的内核的Grid和Block
Dimension。

grid_size和block_size是dim3类型的参数,dim3是CUDA的数据结构类型,是一组整数,用于描述块和网格的尺寸。
Launch Kernel(启动核函数)
更细致观察程序流程
由于CPU与GPU并不共享内存,在执行核函数过程中伴随着数据的传输与copy,流程如下:

注意:在Launch
Kernel这一步骤,伴随着数据从DRAM到各grid(或者说thread)的流动。
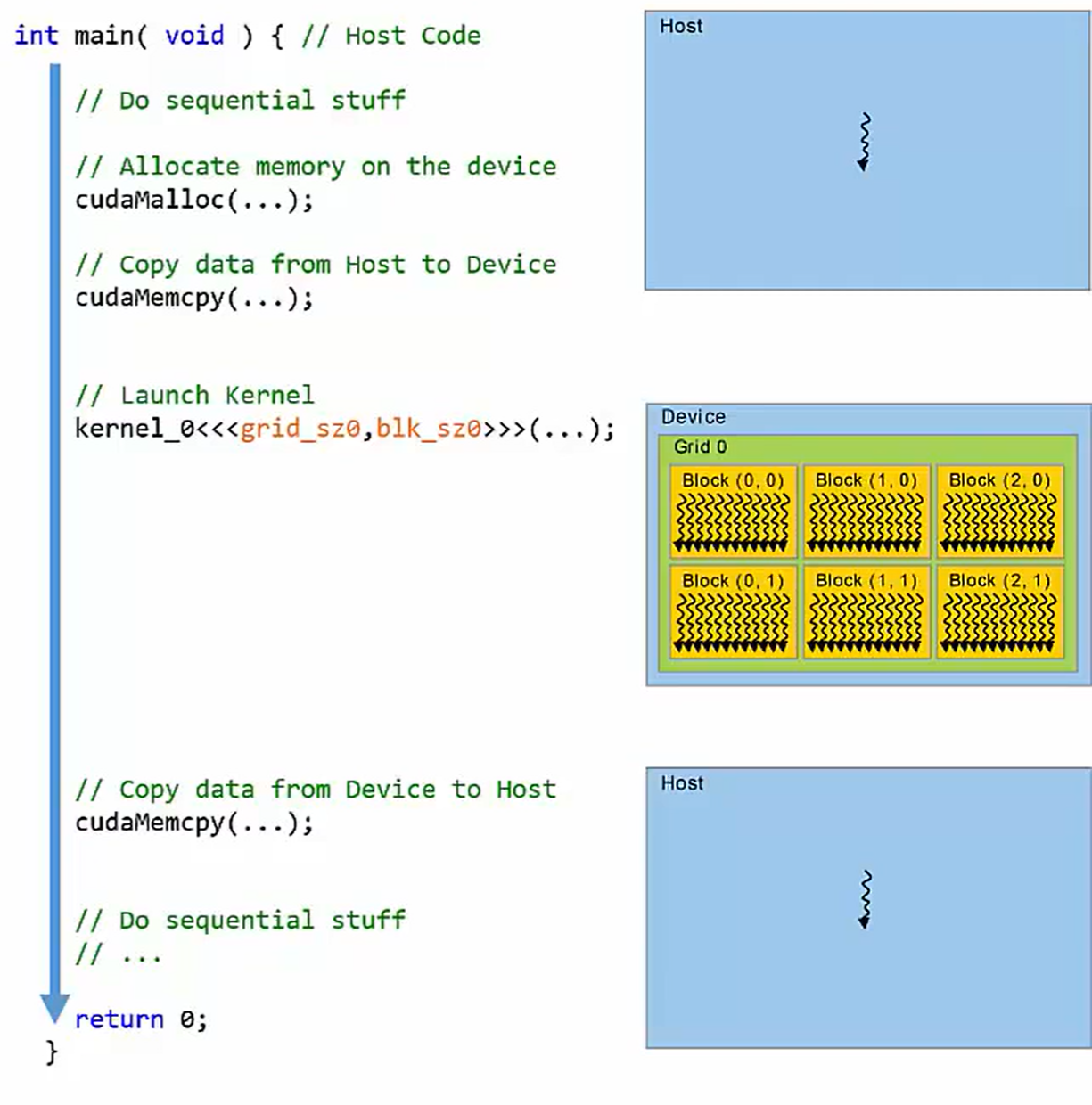
注意:由于数据从Host到Device的拷贝经由PCI-e总线,所以速度很慢,这一点是限制性能的主要原因。
分配Device内存
1 | //在cuda中分配内存 |
数据在Host与Device之间的双向拷贝
1 | cudaMemcpy(dst,src,numBytes,direction) |
numBytes = N*sizeof(type)
direction
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
例子
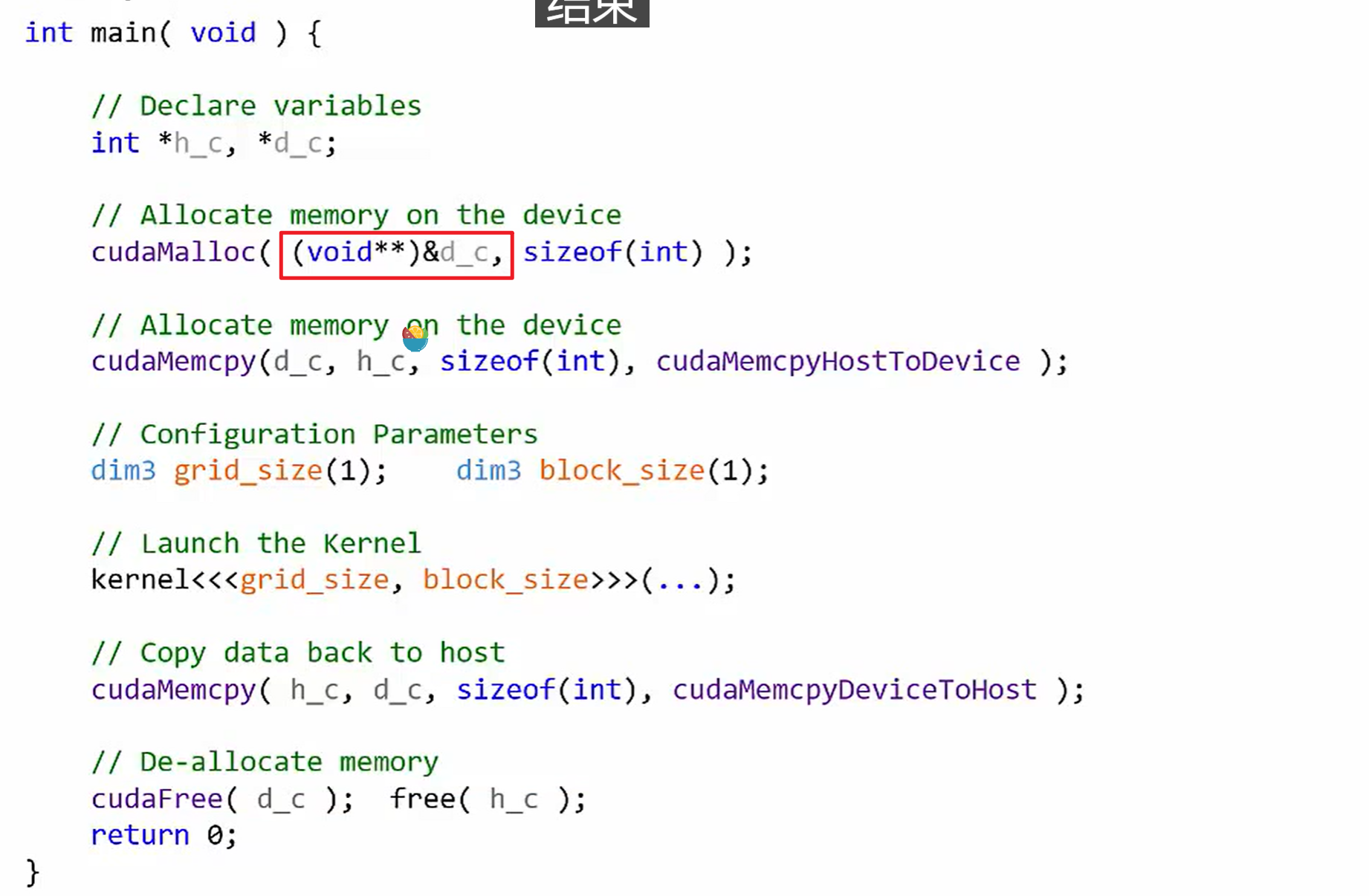
注意:
- 有一个(void**)&,这一句的含义解释:
(void**)&必须是本质上就是指针变量的地址才可以做这样的转换,并不是说把一个一级指针也可以转换,void**的本质是标识一个二级指针。&data就是(默认数据类型**)&data,(void**)&data和&data还是同一块内存,只不过数据类型发生变化了。在这里是为了吧数据类型变成void
- 惯例:由于设备的指针和host混淆引用会导致程序崩溃,因而,在定义变量时候尽量明确,h_代表host变量,d_代表device变量。