CUDA编程笔记:简明扼要-1
这是一篇关于CUDA编程高级概念的笔记
FROM:CUDA Teaching Center Oklahoma State University
Note:本教程并不过多关注细节语法等内容,而是站在更高层次的概念之中。熟练的掌握CUDA编程需要练习,然而对基础概念的把握却需要透彻的理解。
Part1:高级概念
GPU与CPU的不同
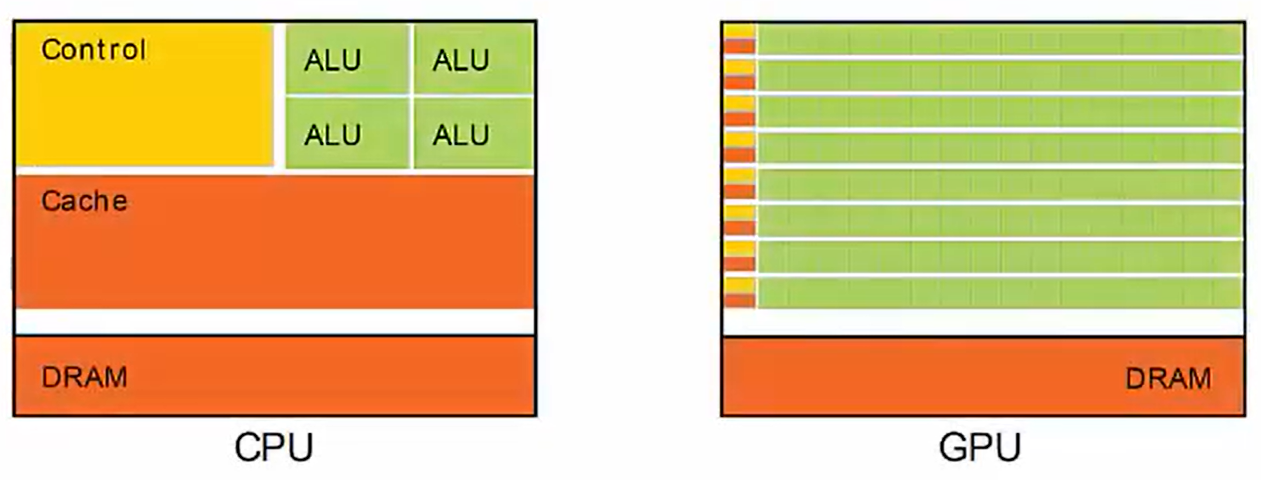
CPU以减少延迟为目标
大量的硅片面积被用于实现复杂控制逻辑、大容量缓存。
适用于通用程序,例如操作系统。
GPU以高吞吐量为目标
大量的硅片面积被算术逻辑单元(nvidia称之为CUDA core)占用
更适合解决可以用并行计算解决的问题,即为:在不同的数据元素上执行相同的程序指令。
对控制逻辑的复杂程度要求较低
如何应用大量的CUDA核心?
要求是:计算任务能够分解为可以在cuda中并发运行的线程。
此处的线程被称为kernel的特殊函数定义。
kernels
- Functions that run on the GPU
Threads
- Kernels execute as a set parallel threads
内核的执行称为内核启动,内核启动之后,作为一组线程执行,每个线程都映射到GPU的单个CUDA
core。
个人理解:每一个cuda核都执行一个线程,整个核函数要启动多个线程,所以称为一组线程
概念与术语
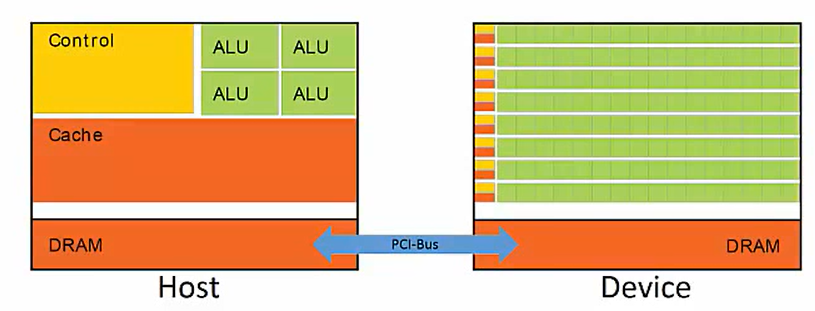
在编程过程中,CPU、GPU都有自己的专有存储区域
HOST(主机)
- CPU + its on-chip memory
Device(设备)
- GPU + its DRAM (存疑,自己修改的,原文是:Host + Device)
Heterogeneous(异构)
Host + Device
发挥两者各自的优势
CUDA
- 扩展的C语言,用于异构编程
CPU擅长串行程序。CPU的任务是,如果运行到大量并行计算的代码部分,该部分代码可能会导致程序流程出现瓶颈,因为CPU并不是为大规模并行吞吐量设计的,由于GPU适合需要大规模并行计算的代码部分,我们希望upload这部分代码到GPU运行。
这种同时使用Host和Device的方式,被称为异构。为这种方法写代码,就称为异构编程(这正是CUDA的用武之地)。
在GPU与CPU协同工作时,主机程序通常控制CUDA程序,每当我们遇到可以大规模并行处理的代码段,传统的软件会在CPU执行,并行程序的执行将会通过PCI-e总线被传递到Device,然而,主机和设备之间的数据交换伴随着高昂的成本,因为这种通信相对于主机、设备来说,是非常慢的,由此,我们只希望大规模并行的程序在Device上运行(此处关键点在于对“大”的把握)。
注意:即便是每个线程都在执行相同的操作,但是每个线程所计算的具体数据是不同的,这可能就会导致:被同一个kernel所启动的不同线程,会有不同的执行速度(这就比如:你算1x1,而有的核算的是5000*5000)
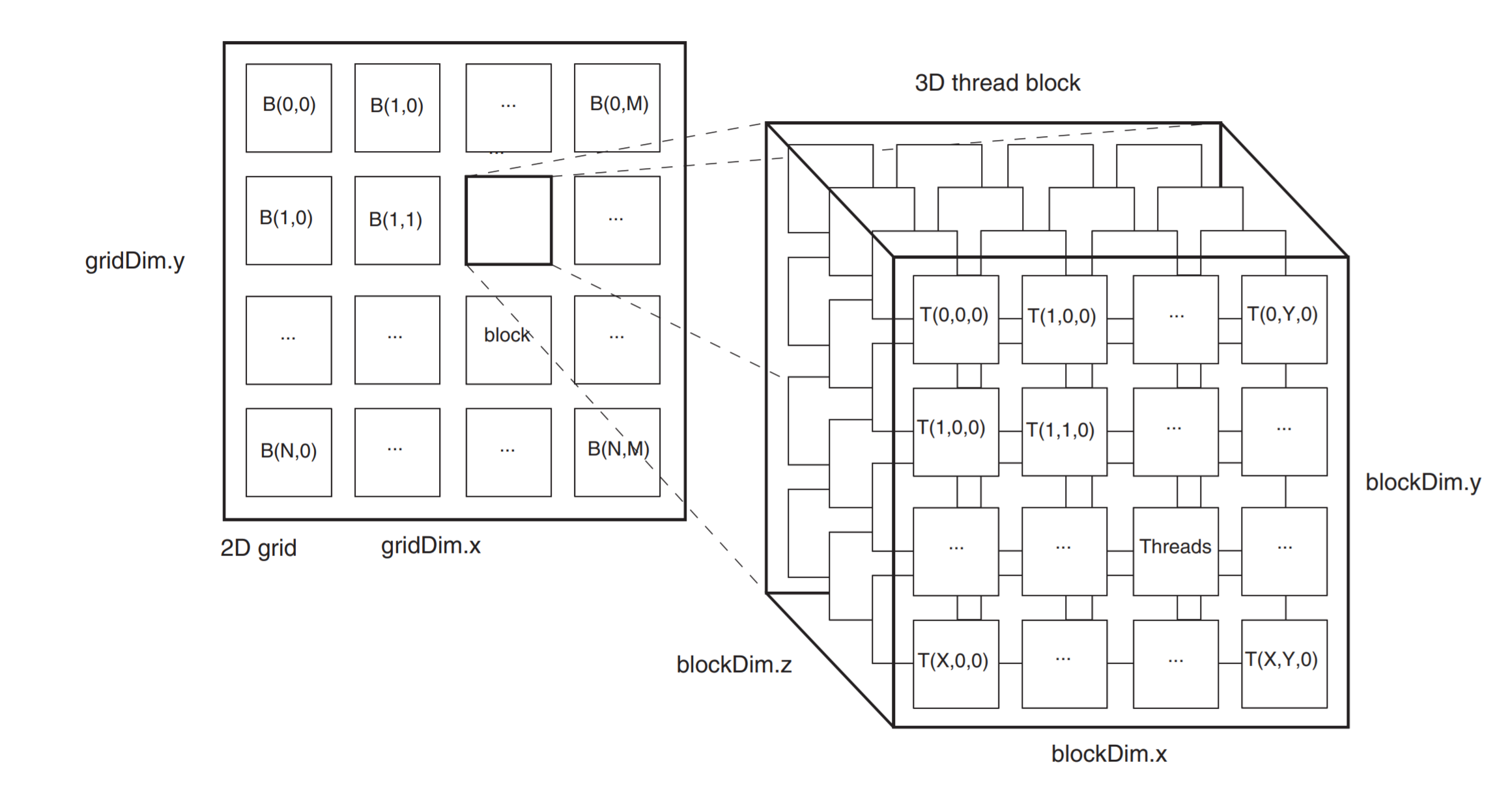
线程的组织层次
如何组织线程使之与GPU上的内核匹配是CUDA编程中最重要的概念之一。
Threads

我们已经看到了线程,它是内核对单个数据的执行。
当内核启动时,每个线程都映射到 GPU 上的一个 CUDA 核心。
Blocks
接下来一个层次是块。当内核启动时,线程集被分组到块中,这些块被映射到相应的CUDA核心集。(集:set)

Grid
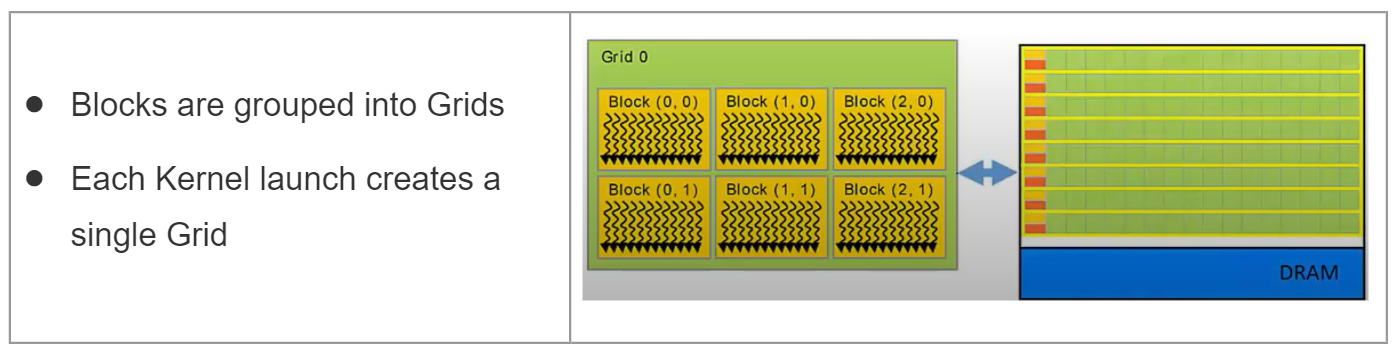
一个Kernel(认为是核函数)作为一个Grid来执行,这个Grid映射到整个设备(GPU及其内存)
块与网格的维度
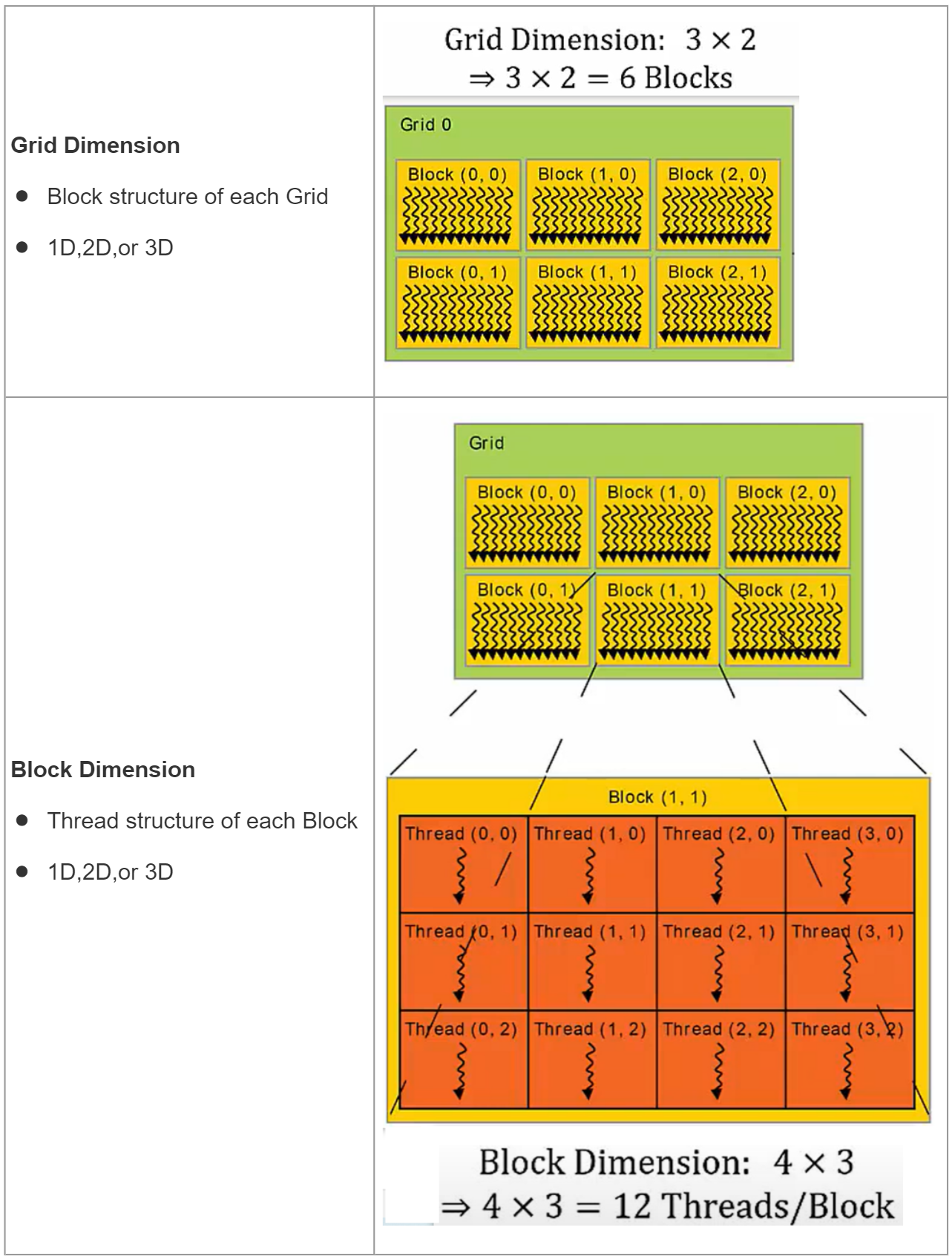
根据上图所示,启动该Kernel时,有72个线程将在GPU上同时执行。

3D可视化线程组织图